1. Mode "ligne dommande" de linux
1.1. Objectifs
À l’issue de cette activité, vous devez être capable :
-
d’utiliser l’interpréteur de commande Linux pour exécuter des commandes
-
de parcourir les pages de manuel pour trouver l’aide sur une commande particulière
-
de vous déplacer dans l’arborescence de fichiers d’un système Linux depuis la ligne de commande
-
de créer/supprimer des fichiers ou des répertoires depuis la ligne de commande
-
d’interpréter/changer les droits d’accès aux fichiers
-
d’expliquer et de mettre en place des liens matériels et symboliques sur des fichiers
-
de mettre en pratique les différents mécanismes liés aux méta-caractères du shell (jokers, redirection, tubes…)
-
de visualiser/contrôler/tuer les processus du système
-
d’afficher/configurer les paramètres d’une interface réseau
-
de tester l’accès réseau
1.2. Pré-requis
-
Notions de base sur les systèmes d’exploitation.
1.3. Conditions
-
Activité su PC Linux Ubuntu avec connexion internet
-
Niveau première
-
Type d’activité Cours/TP
-
Durée : 4h
1.4. Rubriques du programme :
-
Systèmes d’exploitation
-
Identifier les fonctions d’un système d’exploitation
-
Utiliser les commandes de base en ligne de commande
-
Gérer les droits et permissions d’accès aux fichiers.
-
-
Transmission de données dans un réseau
-
Configurer une interface réseau
-
Tester une connexion réseau
-
2. Introduction
Linux est un système d’exploitation libre multi-tâches et multi-utilisateurs.
Cette dernière caractéristique permet à plusieurs utilisateurs d’utiliser le système simultanément.
Afin de définir les limites d’utilisation du système pour chaque utilisateur, on attribue à chacun d’eux un compte utilisateur.
Ainsi, lorsqu’on veut utiliser un système Linux, il faut d’abord se connecter à son compte par une procédure appelée login qui consiste à fournir son identifiant et son mot de passe. Si ceux-ci sont connus du système, on a alors accès au système pour y exécuter des programmes.
Il y a 2 catégories d’utilisateurs :
-
l'administrateur : c’est celui qui, en principe, a installé le système. Il pourra modifier les préférences générales du système et créer de nouveaux comptes utilisateur. Lui seul pourra installer une application modifiant le système. Sous Linux, son nom est généralement root.
-
les utilisateurs “standards” : ce sont les autres utilisateurs du système. Ils ont des pouvoirs et accès limités
Au travers de cette activité, vous découvrirez les moyens d’interagir avec un système linux en utilisant le mode ligne de commande.
3. Interpréteur de commandes
Dans la suite de l’activité, vous allez utiliser exclusivement le système Linux dans un mode appelé ligne de commande. Ce mode qui va vous sembler très “rustique” est cependant très pratique dès lors qu’on désire travailler à distance sur un système Linux (ce qui est souvent le cas lorsqu’on fait de l’administration système).
Pour exploiter ce mode ligne de commande tant redouté mais jamais inégalé , vous allez exécuter un logiciel appelé terminal (ou console). Ce logiciel vous donne accès à un interpréteur de commandes en ligne - on dit aussi shell - dont le rôle est d’offrir une interface vers le système d’exploitation par l’intermédiaire de commandes soit saisies à la main depuis le terminal soit exécutées en séquence depuis un fichier de commandes (ou script) dans lequel elles auront été stockées au préalable.
|
Shell signifie “coquille” en français. On peut donc considérer l’interpréteur de commandes comme une coquille autour du système d’exploitation qui constitue donc le “noyau” (ou kernel en anglais) du système complet. |
A faire : Console de Linux
-
Ouvir un terminal : Cliquer sur Chercher sur votre ordinateur et saisir terminal.
-
Inspecter ce qui s’affiche à l’écran.
Ce qui s’affiche à l’écran s’appelle une invite de commande (ou prompt). Celle-ci indique que l’interpréteur de commandes est en attente de saisie d’une commande.
L’invite de commande est personnalisable mais elle renseigne généralement sur :
-
le nom de l’utilisateur couramment connecté au système ;
-
l’endroit où il se trouve dans l’arborescence de fichiers du système ;
-
le type de compte (“administrateur” ou “standard”).
Par exemple, lorsque je suis connecté en tant qu’administrateur sur ma machine, mon invite de commande est :
marc@topix:/etc #avec :
-
marc@topix -
/etc -
#>$
|
Dans un système Linux, il existe plusieurs interpréteurs de commandes qui possèdent chacun leurs spécificités. Celui utilisé par défaut dans la distribution Ubuntu lorsqu’on lance l’application Terminal est **bash (Bourne Again SHell>. C’est une évolution du shell ancestral des systèmes Unix dont découle Linux. |
4. Commandes
Une commande est une ligne de texte destinée à être interprétée par le shell. Le résultat de l’interprétation mène généralement à l’exécution d’un programme. Le terme “commande” désigne ainsi souvent la ligne de texte qu’il faut saisir et le résultat auquel elle mène suite à son interprétation par le shell (→ exécuter une commande ≈ lancer un programme).
Ce programme prend bien souvent en entrée des options et/ou des arguments qui lui sont fournis par l’intermédiaire de la ligne de commande.
Pour exécuter une commande, il suffit donc de :
-
la saisir suite à l’invite de commande du shell (le nom d’un fichier exécutable par exemple)
-
fournir éventuellement des arguments et/ou options séparés par des espaces
-
lancer l’exécution en enfonçant la touche Entrée ↲ du clavier.
L’exécution d’une commande peut mener à divers résultats :
-
renvoyer de l’information à l’écran ou dans un fichier ;
-
communiquer à travers le réseau ;
-
produire un message d’erreur ;
-
…
4.1. Syntaxe générale des commandes
La syntaxe des commandes, c’est-à-dire la manière dont on doit les écrire, est souvent donnée avec la notation suivante :
commande [option].. . [argument].. .avec :
-
commande -
[option]…
Le caractère facultatif de l’option est indiqué par les crochets et les 3 points indiquent qu’il peut y en avoir plusieurs. -
[argument]…
marc@topix:~> ls -l -a /etc (1)| 1 | cette commande affiche une liste détaillée (→ |
|
Linux fait la distinction entre majuscules et minuscules. On dit qu’il est sensible à la casse (case sensitive en anglais). Ainsi, Cette distinction entre majuscules et minuscules s’appliquent également aux noms de fichiers ou de répertoires. |
Les options peuvent être au format court ou long.
Le format court prend la forme d’un tiret suivi d’une seule lettre (par exemple, -s--version
La plupart du temps, les options courtes ont leurs équivalentes longues (ex. -v--version
Lorsque qu’on donne plusieurs options précédées de tirets simple ou double (→ ---
Si un argument comporte un espace, l’argument doit être entouré de double guillemets.
marc@topix:~> file "compte rendu tp linux.odt"Enfin, il arrive que certaines options nécessitent elle-mêmes des arguments.
Pour le format court, l’argument de l’option est habituellement placé directement suite au nom de l’option (par exemple, -oa.out-oa.out
Pour le format long, il s’agit souvent de séparer le nom de l’option et son argument par le caractère '=' (par exemple --suffix=.bak
A faire : Options d’une commande Linux
La commande uname
-
Exécuter et relever le résultat de la commande
uname -
Exécuter les commandes
uname -nuname --nodename
Que faut-il en déduire sur les 2 options ? -
Exécuter les commandes
uname -o -n -puname -onp
Que faut-il en déduire sur les options courtes ? -
Exécuter la commande
uname--help
Que permet cette option ?
4.2. Catégories de commandes et chemin d’accès
La première chose à savoir est que seul l’administrateur d’un système Linux (utilisateur root
Ensuite, parmi les commandes de base disponibles dans le shell, il faut en distinguer 2 types :
-
les commandes internes dont le code est totalement intégré dans l’exécutable correspondant au shell (→ builtins).
Ex. :cdhistory
Outre les services qu’elles rendent, elles sont bien adaptées à l’écriture des fichiers de script shell évoqués plus haut. -
les commandes externes qui sont des fichiers exécutables à part entière.
Ces fichiers se trouvent notamment dans les répertoires/bin/usr/binusr
|
A faire : Commande interne vs. commande externe
-
La commande
whereis-b
Localiser et relever l’emplacement de la commandehalt
whereis -b halt-
Localiser l’emplacement de la commande
ls -
Utiliser
whereis -
Afficher et relever l’ensemble des répertoires contenus dans la variable d’environnement
PATH -
La commande
type -a -
Déterminer le type des commandes suivantes :
-
history -
halt -
pwd
-
Comme indiqué en début de chapitre, les commandes peuvent être également classifiées selon le fait qu’elles sont exécutables par tout le monde ou seulement par l’administrateur.
Dans le travail qui suit, vous allez créer un nouveau compte local pour un utilisateur standard et lancer un interpréteur de commande pour ce compte de façon à vérifier que certaines commandes ne lui sont pas accessibles.
A faire : Commandes privilégiées vs. standards
-
Taper rigoureusement les commandes suivantes :
useradd -m dummy_user (1)
passwd dummy_user (2)| 1 | Crée un nouvel utilisateur dont le nom est “dummy_user” |
| 2 | Crée un mot de passe pour “dummy_user”
|
-
Lancer un shell pour l’utilisateur nouvellement créé :
su --login dummy_user-
Fournir le mot de passe
123456
|
Sauf mention contraire, veiller à exécuter toutes les commandes qui vous seront demandées par la suite depuis l’interpréteur de ce nouvel utilisateur standard. Pour exécuter une commande réservée à l’administrateur depuis le shell d’un utilisateur standard, plusieurs méthodes existent :
|
-
Relever et analyser la nouvelle invite de commande
-
Exécuter depuis le shell de l’utilisateur standard la commande
halt
Que signifie le message qui s’affiche ? -
Afficher le contenu de la variable d’environnement PATH.
Que dire de son contenu par rapport à celui relevé dans l’activité précédente ?
4.3. Documentation d’une commande
Lorsqu’on désire obtenir de l’aide sur une commande, on a vu que la majorité d’entre elles possédaient l’option longue --help
Une documentation plus complète peut être obtenue en consultant les pages de manuel intégrées à Linux.
La page de manuel d’une commande est obtenue en tapant la commande man
$ man groups
La structure des pages du manuel est assez semblable d’une page à l’autre. On retrouve :
-
le nom et une courte description ;
-
le synopsis c’est-à-dire la syntaxe générale de la commande avec une indication de l’emplacementet des différents arguments et options ;
-
la description complète de la commande ;
-
la liste des options, autant courtes que longues, et leurs éventuels arguments ;
-
l’auteur de la commande et les informations sur les droits d’auteur ;
-
des références vers d’autres commandes pertinentes dans la même catégorie.
Comme les pages de manuel regroupent l’ensemble de la documentation relative à Linux, il arrive parfois que plusieurs pages soient associées à un même nom. Lorsque cela se produit, un numéro est demandé pour aiguiller vers la documentation souhaitée.
timemarc@topix:/home/marc> man time
Man: find all matching manual pages (set MAN_POSIXLY_CORRECT to avoid this)
* time (1)
time (n)
time (3am)
time (2)
time (7)
time (1p)
time (3p)
Man: What manual page do you want?
Man:Celui-ci peut effectivement représenter une commande mais aussi une fonction en Langage C.
Pour afficher une page de manuel particulière pour le mot clé timetime
Ainsi, pour obtenir la page de manuel de la commande time
Les différentes catégories sont les suivantes :
-
1 : commandes générales (pour l’interpréteur de commande);
-
2 : appels système (fonctions du langage C);
-
3 : fonctions de la librairie standard C et d’autres librairies;
-
4 : fichiers spéciaux et pilotes;
-
5 : format de fichiers de configuration et de protocoles;
-
6 : jeux;
-
7 : autres.
Pour un accès direct à la page de manuel de la commande timeman
Ex. : man 1 time
|
Pour obtenir de l’aide sur ce qu’il est possible de faire lors de l’affichage d’une page de manuel (se déplacer, rechercher du texte, quitter…), il suffit de taper sur la touche H du clavier. |
A faire : Page de manuel d’une commande
-
Afficher la page de manuel de la commande
uname -
Donner les touches ou séquences de touches à taper pour :
-
se déplacer d’une page vers le bas
-
se déplacer d’une page vers le haut
-
fermer la page de manuel (c-à-d quitter la commande
man -
se déplacer au début de la page de manuel
-
se déplacer à la fin de la page de manuel
-
rechercher du texte
-
-
Donner la signification des options
-o-puname -
Indiquer à quoi revient d’appeler la commande
uname
4.4. Aide à la saisie des commandes
Comme les commandes Linux sont souvent longues à saisir, diverses facilités sont offertes :
-
"l’auto-complétion"
-
l’historique des commandes ;
4.4.1. Auto-complétion
Lorsqu’on tape une ligne de commande incomplète, l’interpréteur peut nous aider à la compléter si on appuie sur la touche tabulation ↹ du clavier.
Suivant le contexte, il peut nous proposer de compléter automatiquement le nom de la commande ou le nom d’un fichier fourni en tant qu’argument à une commmande.
Si l’interpréteur ne trouve pas de correspondance ou, au contraire, dispose de plusieurs propositions, il ne fait rien mais un 2ième appui sur la touche tabulation ↹ provoque l’affichage des différentes propositions lorsqu’elles existent. Ne reste plus à l’utilisateur qu’à lever l’ambiguité en tapant les prochaines lettres de la commande ou nom de fichier désiré. Dès qu’aucune ambiguité ne subsiste, un 3ième appui sur tabulation ↹ complète automatiquement le reste de la commande ou du nom de fichier.
Si trop de propositions existent lors de l’auto-complétion, l’interpréteur demande confirmation avant de les afficher.
mysqladminmarc@topix:~ > libr (1)
marc@topix:~ > libreoffice
[.. .]
marc@topix:~ > m (2)
Display all 141 possibilities? (y or n)
marc@topix:~ > mysql (3)
mysql mysqld_safe mysql_install_db
mysqladmin mysqld_safe_helper mysql_secure_installation
mysqlbinlog mysqldump mysqlshow
mysqlbug mysqldumpslow mysql_upgrade
mysqlcheck mysql_fix_extensions
mysqld_multi mysqlimport
john@topix:~> mysqla (4)
john@topix:~> mysqladmin
[.. .]| 1 | On veut lancer LibreOffice. On tape |
| 2 | On sait que la commande associée à notre client d’administration MySQL commence par ‘m’ ⇒ on tape ‘m’ puis sur tabulation ↹ ⇒ rien ne se passe ⇒ on appuie une 2ième fois sur tabulation ↹. Trop de commandes commencent par ‘m’ ⇒ bash demande s’il faut vraiment afficher toutes les propositions ⇒ on tape ‘n’ |
| 3 | On se rappelle maintenant que la commande commence par ‘mysql’ ⇒ on tape ‘ysql’ puis tabulation ↹ ⇒ rien ne se passe ⇒ on appuie une 2ième fois sur tabulation ↹ ⇒ bash a trouvé 17 commandes qui commencent par ‘mysql’ |
| 4 | En la voyant dans la liste des commandes proposées, on sait à présent que notre commande est |
A faire : Auto-complétion
Utiliser l’auto-completion pour exécuter les commandes suivantes sachant qu’elle fonctionne non seulement pour les noms de commande mais aussi pour les noms de fichiers :
-
cat /proc/cpuinfo -
file /etc/X11/xinit/xinitrc
4.4.2. Historique des commandes
L’historique des commandes est une liste numérotée qui recense les dernières commandes tapées dans la console. Cet historique est accessible en tapant la commande history
Si la liste est trop longue pour être affichée sur un écran, on aura recours à la commande history | lessfbq
Pour relancer une commande dont on connait le numéro, il suffit alors de saisir, depuis l’invite de commande, son numéro précédé du caractère `!' (sans espace) puis valider en enfonçant la touche Entrée ↲ du clavier.
uname -amarc@topix:~> history
1 2014-09-09 16:37:20 history
2 2014-09-09 16:37:46 uname -a
3 2014-09-09 16:38:10 whereis whereis
4 2014-09-09 16:38:16 history
marc@topix:~> !2 (1)
uname -a
Linux topix 3.11.6-4-desktop #1 SMP PREEMPT Wed Oct 30 18:04:56 UTC 2013 (e6d4a27)
x86_64 x86_64 x86_64 GNU/Linux
marc@topix:~>| 1 | On saisi, précédé du caractère "!", le n° de la commande |
On peut aussi parcourir les précédentes lignes de commandes avec les touches UP ↑ et DOWN ↓ du clavier. Ceci permet très facilement de reprendre une précédente commande pour l’éditer et la modifier. C’est d’ailleurs cette méthode que l’on a tendance à utiliser en priorité…
A faire : Historique des commandes
-
Afficher l’historique de vos commandes
-
Relancer l’avant dernière commande
-
Taper la commande
!-3 -
Taper la commande
history -c-c
5. Commandes liées au système de fichier
5.1. Organisation du système de fichiers
Le système de fichiers d’un système d’exploitation correspond à la façon dont il va stocker, lire et organiser les informations sur le disque dur ou tout autre périphérique de stockage.
On peut assimiler l’organisation des informations d’un système de fichiers à celle mise en place par une bibliothécaire : les données figurent dans des ouvrages (→ fichiers) qui sont normalement regroupés par sujet sur des étagères (→ répertoires), elle-mêmes appartenant à des rayons (→ répertoires de plus haut niveau) situés dans la bibliothèque (→ répertoire principal appelé répertoire racine). L’emplacement et les caractéristiques d’un ouvrage sont alors répertoriés dans une base de données documentaire (→ table d’allocation de fichier) maintenue par la biblitohécaire (→ système de fichiers).
Linux prend en charge plusieurs plusieurs types de système de fichiers mais celui qui est encore le plus communément utilisé est le système EXT4 (EXTended file system v4). Il est néanmoins de plus en plus remplacé par un système de fichiers à priori plus performant appelé BTRFS. On trouve aussi parfois le système de fichier XFS qui peut être, dans certains cas, plus performant que BTRFS.
Malgré sa prise en charge native de EXT4, BTRFS et XFS, Linux est cependant capable d’accéder en lecture/écriture aux informations des systèmes de fichiers créés par Microsoft pour son système Windows (FAT, FAT32, NTFS).
Contrairement à Windows, un système Linux ne comporte qu’une seule arborescence de répertoires qui débute par le répertoire principal appelé répertoire racine (root en anglais) et désigné par le symbole ‘/’.
|
Ne pas confondre le répertoire root avec l’utilisateur root. |
Sous Windows, chaque périphérique de stockage (disque dur/partition, DVD, …) dispose de sa propre arborescence de fichiers qui débute par la lettre qui lui est attribuée (ex. : C:\
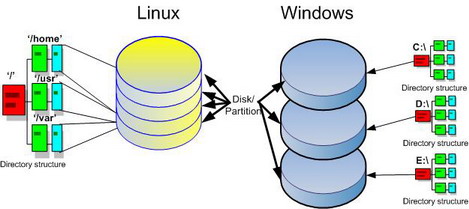
Ci-dessous figure une liste des répertoires standards que l’on peut retrouver dans le répertoire racine de pratiquement toutes les distributions Linux (OpenSUSE, Ubuntu, Debian, RedHat, Slackware, Arch …).
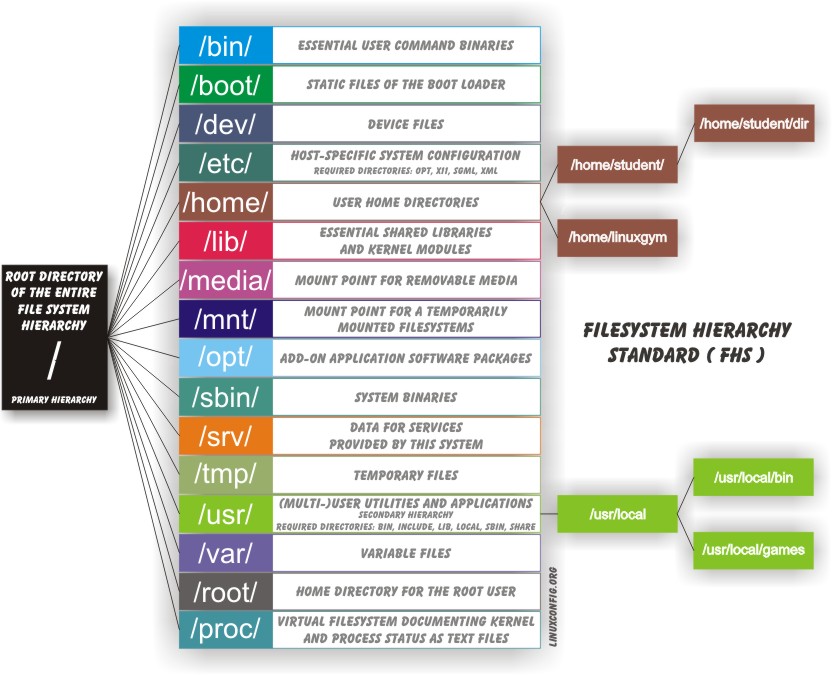
-
/bin -
/boot -
/dev -
/etc -
/home -
/lib -
/media/mnt -
/root -
/sbin -
/tmp -
/usr -
/var
5.2. Les chemins d’accés absolus et relatifs
On a vu jusqu’à présent que pour accéder à un fichier particulier, on spécifiait son emplacement — ou chemin d’accès (path en anglais) — en précédant son nom par la totalité des répertoires à traverser depuis le répertoire racine en les séparant par le caractère slash (/
data.txt/home/marc/Documents/marc@topix:/> less /home/marc/Documents/data.txtUn chemin absolu peut également débuter depuis le répertoire de l’utilisateur courant (/home/<user><user>~
Le même exemple que ci-dessus mais accès en utilisant le “raccourci” ~/home/marc
marc@topix:/> less ~/Documents/data.txtIl existe une autre manière de spécifier l’emplacement d’un fichier ou répertoire — nommée chemin relatif — qui est basée sur la notion de répertoire courant. Ce dernier représente le répertoire dans lequel l’utilisateur se trouve actuellement. Son emplacement peut évoluer au cours du temps en utilisant par exemple la commande cd
Le répertoire courant peut être obtenu :
-
en regardant l’invite de commande
marc@topix:~/Downloads> (1)| 1 | Le répertoire courant est
|
marc@topix:~/Downloads> pwd (1)
/home/marc/Downloads
marc@topix:~/Downloads>| 1 | On demande au shell d’afficher le répertoire courant avec la commande |
Pour spécifier le répertoire courant dans une commande, on utilise le point (‘.’).
marc@topix:~> cd ./Downloads (1)
marc@topix:~/Downloads>| 1 | On demande au shell de se déplacer dans le répertoire |
Le répertoire qui contient le répertoire courant est appelé le répertoire parent. Pour y faire référence dans une commande, on utilise 2 points (‘.. ’).
Ci-dessous un ensemble de commandes qui illustrent l’utilisation des chemins absolus et relatifs.
marc@topix:~/Downloads> cd /usr/bin (1)
marc@topix:/usr/bin> cd ~/Downloads/ (2)
marc@topix:~/Downloads> cd .. (3)
marc@topix:~> touch ./Documents/compte_rendu.txt (4)
marc@topix:~> cd .. /.. /usr/local/ (5)
marc@topix:/usr/local>| 1 | Quel que soit le répertoire courant, on se déplace à l’aide d’un chemin absolu dans |
| 2 | On se déplace dans le sous répertoire |
| 3 | On se déplace avec un chemin relatif dans le répertoire parent de |
| 4 | On crée un fichier vide |
| 5 | On se déplace dans le répertoire |
A faire : Chemins absolus et relatifs
Relever les commandes qui permettent d’obtenir les changements de répertoire suivants lorsque le répertoire courant est celui auquel a mené la commande précédente :
-
Se déplacer dans le répertoire de l’utilisateur courant de manière absolu en utilisant le
~ -
Se déplacer avec un chemin relatif dans
/home -
Se déplacer avec un chemin relatif dans
/usr -
Se déplacer avec un chemin relatif dans
/usr/local/bin -
Se déplacer avec un chemin relatif dans
/usr/bin -
Se déplacer avec un chemin absolu dans
/home/dummy_user/public_html
|
Dans la suite du document et ce, dans un soucis d’alléger l’affichage, l’invite de commande ne sera plus reproduite en intégralité dans les exemples de commandes. Seul le type de shell, standard ou administrateur, sera respectivement signalé par Exemples :
|
5.3. Les droits d’accès
Sous linux, tout fichier ou répertoire appartient à un utilisateur unique : celui-ci est désigné comme le propriétaire du fichier ou du répertoire.
D’autre part, chaque utilisateur (sauf l’utilisateur root) est membre d’un groupe d’utilisateurs.
Le propriétaire peut ainsi décider de partager ou non ses fichiers avec les membres de son groupe voire même avec l’ensemble des utilisateurs du système que l’on appelle (avec un certain mépris) les “autres” (others).
Le propriétaire par défaut d’un fichier est celui qui l’a créé. Toutefois, l’utilisateur rootchown
# chown nomNouveauProprietaire nomFichierLes fichiers, tout comme les répertoires, possèdent 3 séries de droits d’accès :
-
Ceux du propriétaire,
-
Ceux du groupe d’utilisateurs auquel appartient le propriétaire,
-
Ceux de tous les autres utilisateurs.
Chaque série spécifie les droits en lecture (read), en écriture (write) puis en exécution (execute) pour chaque fichier. Le droit d’exécution pour un répertoire signifie simplement qu’on peut le traverser pour accéder à un de ses fichiers ou sous-répertoires.
Les droits d’un fichier/dossier sont visualisables à l’aide de la commande : ls -l nomFichierOuRepertoire
$ ls -l .profile
-rw-r--r-- 1 marc users 1028 Aug 31 19:36 .profileLe 1ier groupe de 3 caractères qui suit le 1ier tiret (rw-.profile
|
Le nom du fichier utilisé pour l’exemple débute bien par un Sous Linux, un fichier (ou répertoire) dont le nom débute par un |
Le groupe de 3 caractère suivant (r--users.profile
Les 3 derniers caractères (r--
La commande dédiée au changement des droits d’accés est la commande chmod
Seuls le propriétaire du fichier et l’utilisateur root
Une des caractéristiques de cette commande est qu’elle applique des droits d’accés qui peuvent lui être fournis en représentation octale (nombre en base 8).
Par convention la présence d’un droit est noté par un bit à 1, l’absence par un bit à 0. On peut donc coder l’ensemble des droits sur 3 groupes de 3 bits.
$ chmod 760 monscript.sh
$ ls -l
total 0
-rwxrw---- 1 marc users 0 Sep 16 15:11 monscript.shCette commande applique les droits suivants au fichier monscript.sh
-
Lecture + écriture + exécution pour le propriétaire : en effet, 7 en octal se code 111 en binaire
-
Lecture + écriture pour les membres du groupe : 6 en octal = 110 en binaire
-
Aucun droit pour les autres : 0 en octal = 000 en binaire
Il est également possible de fournir les droits sous forme symbolique (avec des lettres et des signes ‘+’ ou ‘-’).
$ chmod u+rwx,g+rw,o-rwx monscript.sh (1)| 1 | on ajoute les droits |
A faire : Interprétation des droits d’accès des fichiers/répertoires
-
Interpréter les droits du fichier
/var/log/lastlog -
Interpréter les droits du fichier
/usr/bin/hexdump -
Interpréter les droits sur le répertoire personnel de l’utilisateur
dummy_user -
Que peut bien signifier le
ddummy_user/
5.4. Commandes principales
Le tableau ci-dessous recense quelques commandes de base liées au système de fichier :
| Commande | Description | Exemple |
|---|---|---|
|
Change Directory : Permet de se déplacer dans les dossiers. |
|
|
List : Liste les fichiers d’un dossier. |
|
|
CATalog : Affiche le contenu d’un ou plusieurs fichier(s). |
|
|
CoPy : Copie un fichier |
|
|
ReMove : Supprime un fichier ou un dossier non vide |
|
|
MaKe DIRectory : Crée un répertoire. |
|
|
ReMove DIRectory : Supprime un répertoire vide. |
|
|
MoVe : Déplacer ou renomme un fichier. |
|
|
Met à jour l’heure du fichier mais est utilisé traditionnellement pour créer un fichier vide |
|
|
Renseigne sur le type du contenu d’un fichier |
|
|
Retrouve l’emplacement d’un fichier. |
|
A faire : Commandes de gestion de fichiers
Retranscrire dans le compte rendu, les commandes utilisées pour réaliser les actions suivantes :
|
Ne pas hésiter à consulter les pages de manuel des commandes. |
-
Manipuler un dossier ou un fichier
-
Créer les dossiers
Documents/Downloads/ -
Se déplacer dans le dossier
~/Documents/ -
Créer un nouveau dossier dans
~/Documents/ExoShellDocuments/ -
Supprimer le répertoire
ExoShell -
Créer un fichier texte vide nommé
texte.txtDocuments/ -
Créer un répertoire
mesdoc~/Documents/texte.txt -
Renommer le fichier
texte.txtmesdoclinux.txt -
Déplacer le fichier
linux.txt~/Downloads -
Supprimer le fichier
linux.txt -
Supprimer le répertoire
Documents/
-
-
Modification des droits d’accès
-
Relever le nom du propriétaire du dossier
~/Documents/topsecret.txt -
Attribuer la propriété du répertoire
~/Documents/root -
Indiquer le propriétaire du fichier
topsecret.txt -
En tant qu’utilisateur propriétaire de ce fichier, indiquer s’il est possible de lire son contenu ? Pourquoi ?
-
-
Rechercher un fichier ou un dossier
-
À partir du dossier
/home/public_html/ -
À partir du dossier
/home/topsecret.txt -
Chercher dans le répertoire
/var/log
-
-
Suppression d’un dossier non vide
-
Supprimer le dossier
Documents/ -
Recréer le répertoire
Documents/
-
5.5. Liens
Dans l’arborescence Linux, en tapant la commande ls -l
$ ls -l /usr/bin/firefox
lrwxrwxrwx 1 root root 27 Aug 31 19:34 firefox -> .. /lib64/firefox/firefox.shCela signifie que le fichier firefoxfirefox.sh.. /lib64/firefox
On dit que firefoxfirefox.sh
Un lien permet d’accéder au même fichier depuis plusieurs endroits de l’arborescence un peu à la manière d’un raccourci sous Windows.
Pour créer un lien sur un fichier, on utilise la commande ln
Cette commande permet de créer 2 types de lien selon que l’option -s
-
les liens symboliques (soft links)
-
les liens matériels (hard links)
Un lien matériel peut être considéré comme un moyen de donner plusieurs noms à un même fichier.
Un lien symbolique, quant à lui, peut être considéré comme un fichier qui “pointe” sur un autre fichier.
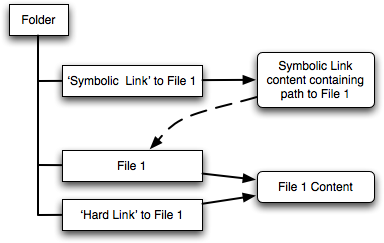
La conséquence de tout cela est que détruire un fichier pour lequel il existe un lien matériel n’empêchera pas d’accéder à son contenu (ceci se fera alors par le biais du lien matériel et non plus à travers le chemin d’accès du fichier d’origine.)
Par contre, si on détruit un fichier sur lequel ne pointe qu’un seul lien symbolique, son contenu est vraiment perdu et le lien symbolique devient, comme il arrive parfois sur internet, un “lien mort”.
Donc, dans le cas de la figure ci-dessus, si on détruit “File 1” son contenu sera encore accessible par “Hard link to File 1” mais plus par “Symbolic Link to File 1”. Si on détruit alors “Hard link to File 1”, le fichier est définitivement perdu.
A faire : Liens symboliques et matériels
-
Dans votre répertoire utilisateur dummy_user, créer un fichier
foobar.txt
$ echo "Hello world" > ~/foobar.txt-
Créer un lien symbolique sur ce fichier avec la commande :
$ ln -s foobar.txt foobar_soft.lnk
-
Lister le contenu du répertoire avec la commande
ls -lfoobar.txt -
Créer à présent un lien matériel sur le fichier avec :
$ ln foobar.txt foobar_hard.lnk
-
Lister de nouveau le répertoire avec
ls -lfoobar.txt
Que constatez-vous au niveau de la représentation des liens au niveau de l’affichage ? -
Quelle différence pouvez-vous relever au niveau du nombre affiché entre les droits d’accès et le nom du propriétaire du fichier
foobar.txt
|
Les droits d’accès d’un lien symbolique n’ont pas de valeur. Seuls les droits d’accès du fichier sur lequel il pointent doivent être considérés. |
-
Afficher le contenu de
foobar.txtcat -
Executer la commande
stat foobar.txt foobar_hard.lnk foobar_soft.lnk
Comparer les informations affichées et plus particulièrement les valeurs de “Size”, “Blocks” et “INode”.
|
Les inodes
Sous un système UNIX, un fichier quel que soit son type est identifié par un numéro appelé numéro d' inode. Un inode est une structure qui contient diverses informations sur le fichier auquel il est associé :
$ ls -i mon-fichier Un répertoire n’étant qu’un fichier, il est lui aussi identifié par un inode. Au niveau du disque dur, un répertoire n’est qu’une liste associant des noms de fichiers à des numéros d’inode. La différence entre un lien matériel et symbolique se trouve au niveau de l’inode. Un lien matériel n’a pas d’inode propre : il partage l’inode du fichier vers lequel il pointe. Par contre, un lien symbolique possède son propre inode. À noter qu’on ne peut pas créer de liens matériels entre deux partitions de disque. Cette limitation n’existe pas avec les liens symboliques. |
-
Détruire le fichier
foobar.txtstat foobar_hard.lnk
Que remarquez-vous au niveau de l’information “Links” ? -
Afficher le contenu des 2 liens (matériel et symbolique) avec la commande
cat
Interpréter le résultat. -
Créer un répertoire
dummy
Que pouvez-vous en déduire ?
|
Malgré ce qui vient d’être démontré sur l’impossiblité de créer des liens matériels sur des répertoires, les “raccourcis” |
6. Méta-caractères du shell
Des méta-caractères sont des caractères qui remplacent/décrivent d’autres caractères ou qui prennent un sens particulier dans un certain contexte.
Dans le cadre du shell, ces méta-caractères sont généralement utilisés :
-
pour constituer des motifs qui désignent un ensemble de fichiers/répertoires
→ Ceci sera étudié plus loin dans #file_meta[Caractères génériques associés aux fichiers]. -
pour agir sur le comportement des commandes.
→ Ceci sera étudié plus loin dans #streams[Flux d’entrée/sortie, redirection et tubes]
$ ls /dev/tty* (1)| 1 | Cette commande liste tous les fichiers du répertoire |
Parmi les méta-caractères les plus répandus, on trouve :
-
l’astérisque
* -
le point d’interrogation
? -
le point d’exclamation
! -
les crochets
[] -
les signes
<> -
la barre verticale
| -
l’esperluette
& -
le point virgule
; -
l’antislash
\
Ainsi, lorsqu’ils apparaissent dans des commandes, le shell leur accorde une signification particulière et les traite avant d’exécuter la commande.
;$ echo "Vive " ; uname (1)
Vive (2)
Linux (3)
$| 1 | le |
| 2 | Résultat de la commande |
| 3 | Résultat de la commande |
Des moyens existent cependant pour annuler le sens particulier des méta-caractères au sein des commandes :
-
L'échappement qui annule le sens particulier de tout méta-caractère. Il consiste à précéder le méta-caractère par un antislash (
\
|
Pour annuler le sens particulier de l’antislash, il suffit de le doubler. Exemple : Affichage d’un texte comportant un antislash avec la commande echo
|
-
les guillemets doubles ("…") qui annulent l’interprétation par le shell de certains méta-caractères éventuellement présents dans le texte qu’ils délimitent.
|
L’utilisation des guillemets double ne désactive pas les mécanismes de substitution de commande et de substitution de variables qui seront abordés ultérieurement. |
$ echo le nom de ma machine est <topix>
bash: syntax error near unexpected token 'newline' (1)
$ echo "le nom de ma machine est <topix>"
le nom de ma machine est <topix> (2)
$| 1 | Le signe ‘<’ a été interprété par le shell ⇒ il génère une erreur car la commande n’a alors plus de sens pour lui |
| 2 | les guillemets double ont annulé l’interprétation des signes ‘<’ et ‘>’ ⇒ le texte est affiché tel quel
|
|
6.1. Caractères génériques associés aux fichiers
Les caractères génériques sont des méta-caractères qui vont permettre de désigner un ensemble de fichiers (ou de répertoires) dans une commande sans avoir à les lister individuellement.
$ file /etc/e*
/etc/enscript.cfg: ASCII text
/etc/environment: ASCII text
/etc/esd.conf: ASCII text
/etc/ethers: ASCII text
/etc/exports: ASCII text
$-
le caractère
*Voir exemple ci-dessus.
-
Le caractère
?
/usr/bin$ ls /usr/bin/?b*-
Les crochets (
[]
$ ls a[0123456789]*$ ls a[0-9]*-
Le point d’exclamation est utilisé avec les crochets pour inverser la signification de la plage de valeurs
$ ls [!a]*A faire : Caractères génériques
-
Afficher le type des fichiers (→ commande
file -
Afficher le type des fichiers du répertoire personnel dont le nom débute par ‘D’, se termine par ‘s’ et contient un ‘n’
-
Afficher le type des fichiers de
/etc/ -
Afficher le type des fichiers de
/etc/ -
Afficher le type des fichiers de
/etc -
Afficher le type des fichiers de
/etc/init.d/ -
Afficher le type des fichiers de
/dev/ -
Afficher le type des fichiers de
/dev/
6.2. Flux d’entrée/sortie, redirection et tubes
6.2.1. Flux d’entrées/sorties
Dans Linux, chaque programme dispose par défaut de 3 descripteurs de fichier qui pointent sur des canaux de communication appelés flux ou stream en anglais.
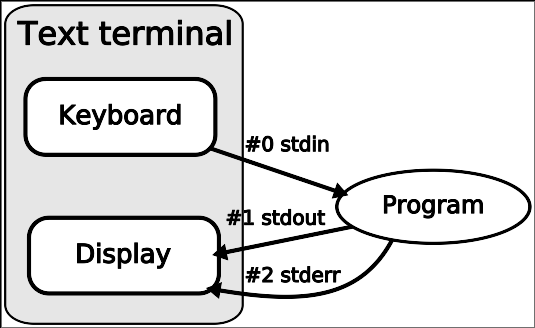
C’est par ces 3 flux que le programme :
-
reçoit les informations qu’on lui communique
⇒ ce flux est appelé STDIN (STandarD INput) et il est généralement alimenté par ce que l’utilisateur tape au clavier -
envoie les informations qu’il produit
⇒ ce flux est appelé STDOUT (STandarD OUTput) et il correspond généralement à l’écran du terminal où s’exécute le programme -
communique les erreurs qu’il peut rencontrer
⇒ ce flux est appelé STDERR (STandarD ERRor) et, lui aussi, est dirigé normalement vers l’écran
6.2.2. Redirection
Le mécanisme de redirection permet, comme son nom l’indique, de rediriger les flux vers ou depuis des fichiers.
Il est ainsi possible de lister le contenu d’un répertoire non pas à l’écran mais dans un fichier de façon, par exemple, à en garder une trace.
Pour cela, on va utiliser le symbole ‘>’ dans la commande suivi d’un nom de fichier pour lui indiquer d’envoyer les informations produites dans ce fichier.
$ ls ~ > listing.txt
$ cat listing.txt
bin
Desktop
Documents
Downloads
Music
Pictures
Public
public_html
sketchbook
Templates
Videos
$|
Lorsqu’un même fichier est spécifié dans plusieurs commandes redirigées avec ‘>’, le contenu de celui-ci ne contiendra que le résultat de la dernière commande. Son contenu est en effet écrasé suite à chaque redirection. Si on désire mettre bout à bout (on dit aussi concaténer) les résultats de chaque commande redirigée, on utilise ‘>>’ au lieu de ‘>’. Exemple : Écrire dans un fichier le nom ainsi que la release du kernel suivis des informations sur la distribution Linux puis afficher le fichier produit
|
Pour rediriger le flux STDERR dans un fichier on va utiliser 2>2
-
0 = STDIN ;
-
1 = STDOUT ;
-
2 = STDERR.
root/run/root/$ ls /r* (1)
ls: cannot open directory /root: Permission denied
/run:
avahi-autoipd.eno16777736.pid lock pcscd udev
[.. .]
$ ls /r* 2> err.txt (2)
/run:
avahi-autoipd.eno16777736.pid lock pcscd udev
[.. .]
$ cat err.txt (3)
ls: cannot open directory /root: Permission denied
$| 1 | On tente de lister les répertoires : |
| 2 | On redirige le flux d’erreur sur le fichier |
| 3 | On affiche le fichier vers lequel STDERR a été redirigé. Celui-ci ne contient alors que les message d’erreur produits par la commande. |
Il est enfin possible de rediriger le flux STDIN avec ‘<’ même si cette opération est plus rare.
$ tr [:lower:] [:upper:] (1)
Ceci représente le texte à convertir en MAJUSCULES. (2)
CECI REPRÉSENTE LE TEXTE À CONVERTIR EN MAJUSCULES. (3)
^C
$ cat foo.txt (4)
Ceci représente le texte à convertir en MAJUSCULES.
$ tr [:lower:] [:upper:] < foo.txt (5)
CECI REPRÉSENTE LE TEXTE À CONVERTIR EN MAJUSCULES.(6)| 1 | On invoque la commande |
| 2 | Sans redirection, la commande attend par défaut la saisie d’un texte au clavier (→ STDIN ). La commande convertit le texte en majuscules lorsqu’on appuie sur la touche Entrée ↲ du clavier |
| 3 | Le résultat de la conversion en majuscules est affiché |
| 4 | On affiche le contenu d’un fichier |
| 5 | On exécute cette fois la commande |
| 6 | On obtient le même résultat |
|
Les redirections sont très intéressantes pour le dialogue avec les périphériques. En effet, sous Linux, les ports séries ou parallèles sont représentés par des fichiers situés dans le répertoire Exemples :
|
A faire : Redirections
-
Que produit la commande
echo "Lorem ipsum" 1> foo.txt1> -
Que signifie selon vous
&>ls /r* &> foo.txt
|
Cette commande peut également s’écrire |
-
Élaborer la séquence de commandes suivante :
-
Lister les répertoires de
/var/logfind-type -
Rejouer la même commande mais en redirigeant uniquement STDOUT vers le fichier
folders.txt -
Rejouer la dernière commande en redirigeant STDERR vers le fichier spécial
/dev/null
Consulter la page de manuel denullman null/dev/null -
Afficher tout en majuscules le contenu de
folders.txttr -
Modifier la commande pour qu’elle envoie le résultat dans un fichier plutôt qu’à l’écran.
-
Que se passe-t-il si le même fichier est spécifié pour la redirection d’entrée et la redirection de sortie ?
-
6.2.3. Tubes (pipe)
Les tubes ou pipes en anglais sont un moyen d’envoyer la sortie d’une commande (← STDOUT) sur l’entrée (← STDIN) de la suivante.
Le schéma suivant illustre ce mécanisme :
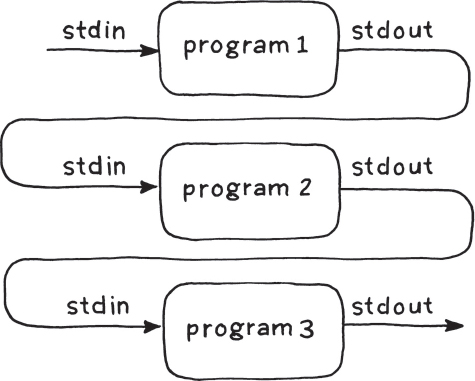
|
Un tube se note à l’aide du caractère ‘|’ (combinaison AltGr+6 sur le clavier).
|
Les tubes sont très souvent utilisés. Il est donc essentiel de bien les maîtriser. |
A faire : Tubes
-
Observer les derniers évènements du système en tapant la commande
dmesg | taildmesgtail
La commandetaildmesg -
Visualiser page par page l’ensemble des évènements du système en tapant la commande
dmesg | less
La commandeless -
Élaborer une commande avec un pipe qui permettra en une seule ligne d’obtenir le même résultat qu’à la dernière question de l’exercice précédent (→ afficher en majuscules les répertoires de
/var/log
7. Gestion processus
Linux est un système d’exploitation multi-tâches et multi-utilisateurs.
De ce fait, il est capable de gérer simultanément un ensemble de programmes lancés par un ou plusieurs utilisateurs.
Un processus ou tâche est une instance d’un programme en cours d’exécution. Ainsi, le fait de lancer 3 fois un même programme provoquera la création de 3 processus distincts.
Un processus est identifié par le système à l’aide d’un numéro appelé PID (Process IDentifier).
Il est souvent utile de connaître, contrôler voire de tuer les processus qui tournent sur une machine.
C’est ce qui va être abordé maintenant.
7.1. Visualiser les processus.
Les 3 commandes les plus utilisées pour visualiser les processus sont :
-
ps -
top -
pstree
A faire : Affichage des processus en cours d’exécution
-
Lancer 2 interpréteurs de commandes puis exécuter dans l’un d’eux la commande
top
Exécuter dans l’autre, les commandes :-
ps -
ps -a
-
-
Interpréter les résultats des 2 commandes.
-
Qu’indique selon vous la colonne TTY ?
-
Parcourir la page de manuel de
ps-
-f -
-e-A -
-l
-
-
Exécuter ces commandes pour observer leurs résultats.
-
Quelle est la signification de la colonne
PPID-f-l -
Qu’indique la colonne
S-l -
Afficher l’arborescence de processus avec
pstree -
Quel est le nom du processus situé à la racine de cette arborescence ? (Celui-ci est le 1ier processus lancé suite de l’initialisation de l’OS).
-
Déterminer son PID.
-
Dans le terminal où s’exécute
top
7.2. Agir sur un processus avec les signaux
Les signaux sont un moyen de communication avec les processus. Linux prend en charge 63 signaux mais seuls un nombre restreint d’entre eux sont utilisés au quotidien.
La façon la plus commune d’envoyer les signaux à un processus est d’utiliser la commande kill
La commande kill
|
Se souvenir que la commande |
Quelques combinaisons de touches permettent également d’envoyer des signaux au processus en cours :
-
Ctrl+C : envoie le signal SIGINT qui provoque généralement l’arrêt du processus
-
Ctrl+Z : envoie le signal SIGTSTP qui demande la suspension du processus
Une autre façon d’envoyer un signal est d’utiliser la commande killall
A faire : Utilisation des signaux
-
Lancer 2 instances de la commande
top -
Consulter la page de manuel de
signal -
Quitter une des instances de
top -
Relancer une instance de
top -
Quitter de nouveau l’instance de
top -
Relancer l’instance de
top -
Taper Ctrl+C et constater que le programme se termine
-
Relancer l’instance de
top -
Taper Ctrl+Z
-
Dans le 3ième terminal, taper la commande
ps -al -
Combien d’instances de
top -
Tuer le processus pour lequel la commande précédente indique ‘T’ dans la colonne ‘S’
-
Relancer la commande
top -
Taper la commande
killall top -
Quelle action est provoquée par cette dernière commande ?
8. Gestion réseau
Linux dispose d’une multitudes de commandes liées au réseau.
Parmi ces commandes, certaines sont couramment utilisées. Ce sont elles que nous allons étudier maintenant.
8.1. Configurer une interface réseau : ifconfig
ifconfigCette commande permet à la fois :
-
d’obtenir des informations sur une interface réseau
-
de configurer une interface réseau
$ ifconfig (1)
$ ifconfig eth0 auto (2)
# ifconfig eth0 192.168.1.15 netmask 255.255.255.0 (3)
# ifconfig eth0 up|down (4)| 1 | Affichage des paramètres réseaux de toutes les interfaces présentes sur la machine |
| 2 | Configuration de l’interface eth0 en automatique (DHCP) |
| 3 | Configuration manuelle de eth0 |
| 4 | Activer ou désactiver l’interface eth0 |
A faire : Affichage de la configuration de l’interface réseau
-
Exécuter la commande
ifconfig-
l’adresse IP qui lui est attribuée (→ inet addr)
-
son adresse MAC (→ HWaddr).
-
|
Adresse MAC
L’adresse MAC est un numéro sur 48 bits (6 octets) figé et stocké dans le dispositif réseau. Elle permet de l’identifier de manière unique à l’échelle mondiale. Les 22 premiers bits identifient le constructeur de la carte réseau. De façon à ce que 2 dispositifs réseau puissent communiquer à travers le réseau, il faut leur associer une adresse IP. Une correspondance directe existe entre les adresses IP d’un réseau et les adresse MAC des dispositifs associés (cette association est mémorisée dans une table élaborée à partir d’échanges utilisant le protocle ARP) |
-
Déterminer si votre carte réseau provient du même constructeur que celle de votre voisin.
-
le masque de sous-réseau (→ Mask)
8.2. Tester une connexion réseau : ping
pingLa commande ping
Elle permet aussi de réaliser des statistiques sur les temps de réponse ainsi que sur le pourcentage de paquets de données perdus.
Pour cela, elle utilise le protocole ICMP en envoyant des messages de type ECHO RequestECHO Reply
Sur Linux, ping
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=128 time=4.62 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=128 time=4.40 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=128 time=4.28 ms
^C
--- 192.168.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 4.288/4.439/4.622/0.158 ms (1)
$| 1 | Les valeurs indiquent les temps de propagation aller-retour (→ rtt = Round Trip Time)
min., moyen et max. des paquets de données ainsi que la déviation standard (→ |
Lorsqu’un ping
-
l’ordinateur qu’on utilise est correctement configuré
-
l’ordinateur interrogé est présent et également correctement configuré
-
le réseau qui relie les ordinateurs est opérationnel.
A faire : Mise en œuvre de ping
Consulter la page de manuel de ping
-
accès à l’interface loopback (notée “lo” dans l’affichage résultant de la commande
ifconfig
|
Interface loopback
Une interface réseau loopback (à ne pas confondre avec le périphérique loopback) n’est rattaché à aucune carte réseau physique. Elle sert à tester en local des programmes utilisant TCP/IP pour communiquer. Elle n’occasionne donc aucun traffic sur le réseau. |
-
accès à la machine de votre voisin en précisant 5 tentatives
-
accès à toutes les machines du réseau en précisant 3 tentatives
-
accès à la machine nommée
localhost-
À quelle interface est associée cette machine ?
-
-
accès au site
google-public-dns-a.google.com-
Quelle est l’adresse IP de ce site ? Facile à mémoriser, non ?
-
-
accès à l’interface loopback APRÈS l’avoir désactivée
9. Nettoyage
Vous arrivez au terme de l’activité de découverte du shell Linux.
L’utilisateur imaginaire dummy_user que vous avez créé pour cette activité n’a plus lieu d’exister sur le système : il est à présent temps de supprimer son compte.
A faire : Bye ! Bye ! Dummy user
Détruire le compte de l’utilisateur dummy_user
# userdel -r dummy_user